
[Opinion] AI sovereignty and China
Something I missed but it comes as no surprise. Pay close attention to China's Draft Interim Measures and the statements of:- 1) "use datasets that conform to the core socialist values and reflect the fine traditional Chinese culture" 2) "ensure the legitimacy and traceability of training data sources, adopt necessary measures to ensure data security, and prevent the risk of data leakage."
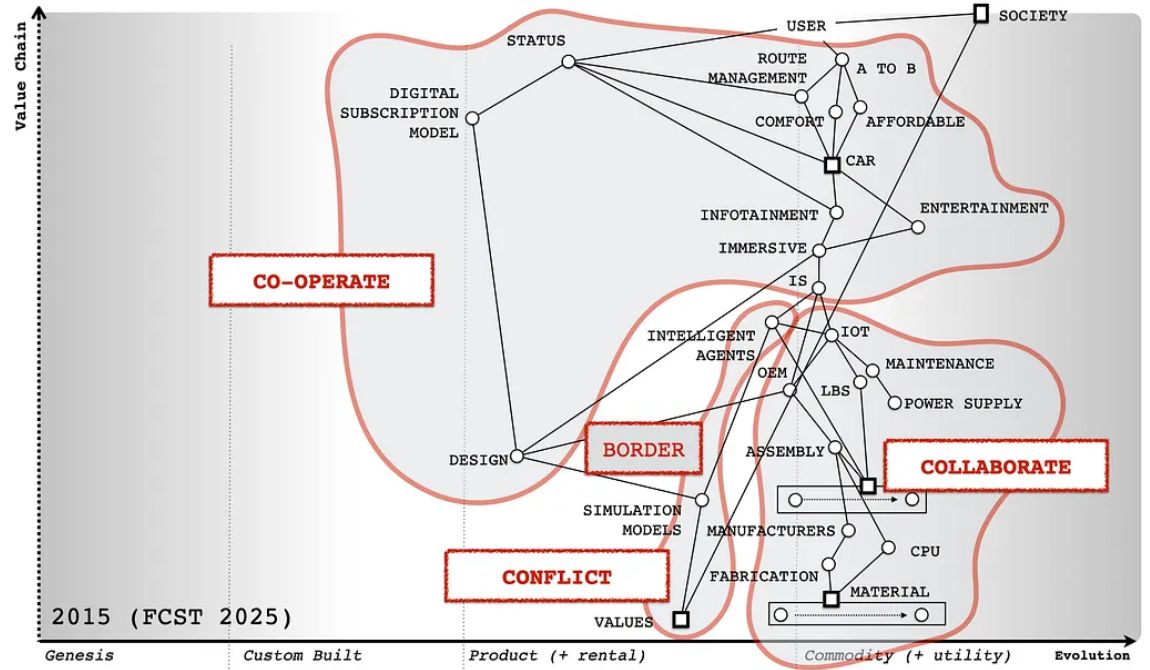
As I noted back in 2015 when I helped the DVLA map out the future of the automotive industry, the values embedded in these "AI" systems are strongly influenced by the training data or what we called simulation systems back then. This is where our borders needed to be in the technological and economic landscapes (see map). I repeated this concern in 2024 in my post on AI and the new theocracies, specifically touching upon how these "systems can significantly shape how individuals reason about the world by functioning as a tool, language processor, and medium for communication".
Maintaining sovereignty has little to do with where the models are hosted (a territorial concern) but instead who controls what they are trained with and how the models are built (a technological/economic concern). The usual counter is to talk about open weights but they are not enough to determine what values are embedded in these systems because you cannot determine the output from weights alone as it requires processing. For this reason, guardrails will never be enough and you have to look at what the systems are trained with.
China has shown it clearly understands this and indicated several times that it is pushing towards a more open path, which ultimately means all the symbolic instructions and that includes training data. However, in order to follow this path, you first have to ensure there is traceability in the training data. Hence you should view this as China positioning itself for a further move toward open training data.
This is where the battle for AI becomes interesting. When China is ready to make that move towards open training data, many US vendors are unlikely to be able to counteract. Not because of copyright infringement and the data they have used (which I'm sure is a factor) but because many vendors would struggle to provide full lineage for the data used in training.
The future of AI seems to be heading towards a crossroads where China will play that open card and present a message of "Verify us, we're open", whilst the US players will offer "Trust us, we're the US". This may help to explain the recent framing of competition between Anthropic and OpenAI in US defence discussions. The rivalry narrative is a blatant attempt to define a market even though both organisations operate within the same regulatory, procurement and national security ecosystem. Someone in US Gov clearly realises the game that is coming.
It's going to get interesting, or in other words "may you live in interesting times" ... as the old British curse goes.
Originally published on LinkedIn.